Building a Real-Time Analytics Platform: Kafka, Flink, and Druid in Action
Explore the design and technical decisions behind a sophisticated real-time advertising analytics platform leveraging Apache Kafka, Flink, and Druid for scalability, speed, and security.
Building a Real-Time Analytics Platform: Kafka, Flink, and Druid in Action
Real-time analytics isn’t just beneficial anymore; it’s essential if you’re serious about staying competitive. Nowhere is this more obvious than in digital advertising. Imagine trying to navigate today’s fast-paced market using outdated information—it’s like driving with last year’s map.
Recently, I found myself leading a fascinating project: designing a real-time advertising analytics platform from scratch. It wasn’t just about technology; it was about enabling businesses to see and respond to the world instantly. Let me take you behind the scenes and share the story of the technical decisions we made, how we tackled scalability, and why reliability became our guiding principle.
Architecture Diagram
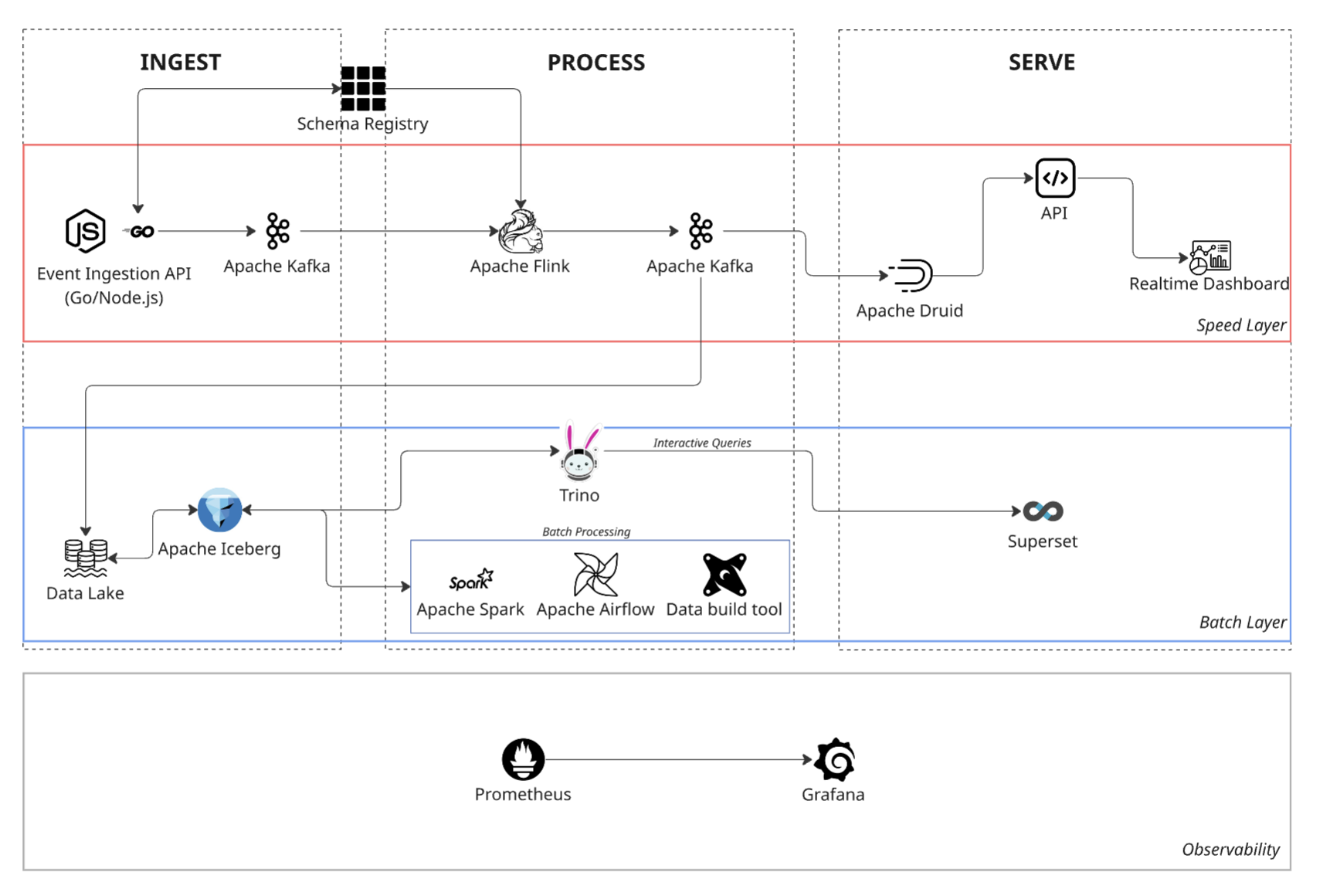
Why Real-Time Analytics?
In today’s advertising world, speed is everything. Advertisers aren’t willing to wait minutes, let alone hours, to know if their campaigns are performing. They need to adjust their strategies on the fly, instantly optimize budgets, and quickly understand their audiences. Metrics like click-through rates, impressions per minute, and cost-per-conversion must update within seconds to keep advertisers agile and informed.
Inside the Tech Stack: Choices and Challenges
Getting Data In: Apache Kafka to the Rescue
When we started thinking about ingesting millions of events per second, Apache Kafka immediately stood out. Kafka is built for scale, offering a distributed, horizontally scalable architecture. We routed events from each client to specific partitions, creating a neat system that segregated data efficiently while also allowing parallel processing. Plus, Kafka’s built-in durability meant we could recover or reprocess data at any time—a crucial safety net for high-stakes analytics.
Processing on the Fly with Apache Flink
Our next big decision was choosing the processing engine. Apache Flink fit our requirements perfectly, offering genuine real-time, event-driven processing capabilities. Unlike batch systems, Flink handles each event individually, ensuring extremely low latency. Its built-in stateful processing and checkpointing capabilities allowed us to guarantee exactly-once processing—no duplicate data, no headaches.
To keep our data clean and insightful, we integrated a Schema Registry for validating event structure and enriched events by cross-referencing cached reference data like demographics. This step made our analytics more powerful, allowing clients to dive deeper into their data.
Instant Insights with Apache Druid
For interactive analytics and rapid queries, Apache Druid was a game-changer. Its direct, real-time ingestion from Kafka made new data instantly available for querying. Thanks to Druid’s columnar storage and advanced indexing, complex queries—like filtering by geography or demographics—could be executed in milliseconds, even at scale.
Druid also offered automated data roll-up capabilities, efficiently managing storage while maintaining high query performance over long periods.
Keeping Data Safe and Accurate
Real-time doesn’t mean cutting corners on data quality or security. We enforced strict schema validation using Avro and Confluent’s Schema Registry, automatically filtering out problematic data to a dedicated dead-letter queue.
Security-wise, multi-tenant isolation was implemented at every level—from Kafka partitions through Flink processing and into Druid. We incorporated RBAC, encryption at rest and in transit, and adhered strictly to GDPR standards, ensuring complete trust and compliance.
Planning for Future Growth
We built this platform with a clear vision: anticipating 10X growth. Kafka’s partitioning and Flink’s parallel processing made horizontal scaling straightforward. For internal teams needing exploratory, ad-hoc analytics, we created a separate data lake using Apache Iceberg and Trino. This approach ensured internal heavy queries wouldn’t disrupt our critical real-time analytics.
Visibility and Reliability
To maintain the platform’s reliability, we set up comprehensive observability using Prometheus for monitoring and Grafana for intuitive visualizations. Tracking Kafka ingestion lag, Flink job latency, and Druid query performance in real-time meant we could catch and address issues immediately, keeping the system robust and dependable.
Looking Ahead: Innovation and Expansion
This project was just the beginning. We’re now excited about integrating advanced capabilities such as anomaly detection and predictive analytics using machine learning. We’re also exploring GraphQL to enhance front-end efficiency and provide an even smoother user experience.
Building a real-time analytics platform was about much more than infrastructure—it was about creating something transformative, enabling businesses to act faster, smarter, and more confidently. By combining Kafka, Flink, and Druid, we’ve not only created a robust, scalable solution; we’ve set the stage for businesses to lead the pack, not just stay in the race.